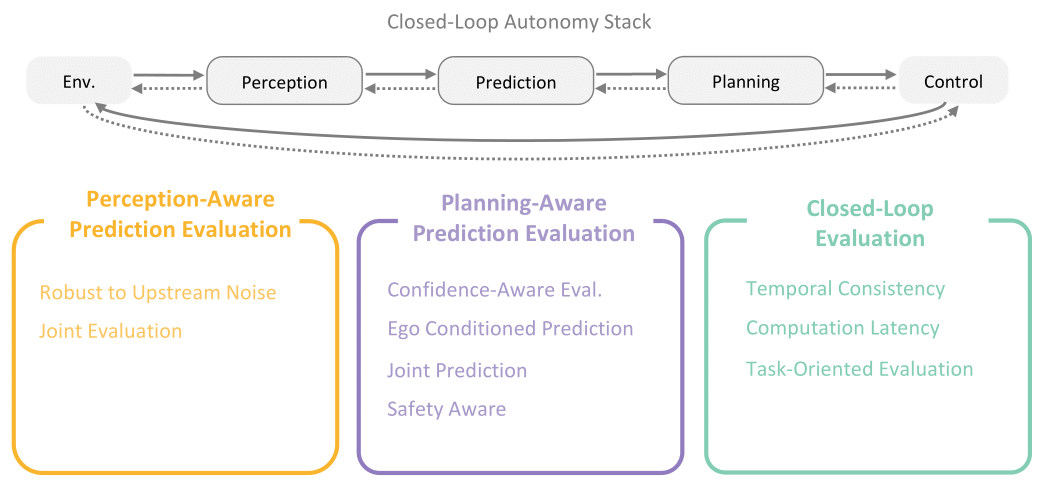
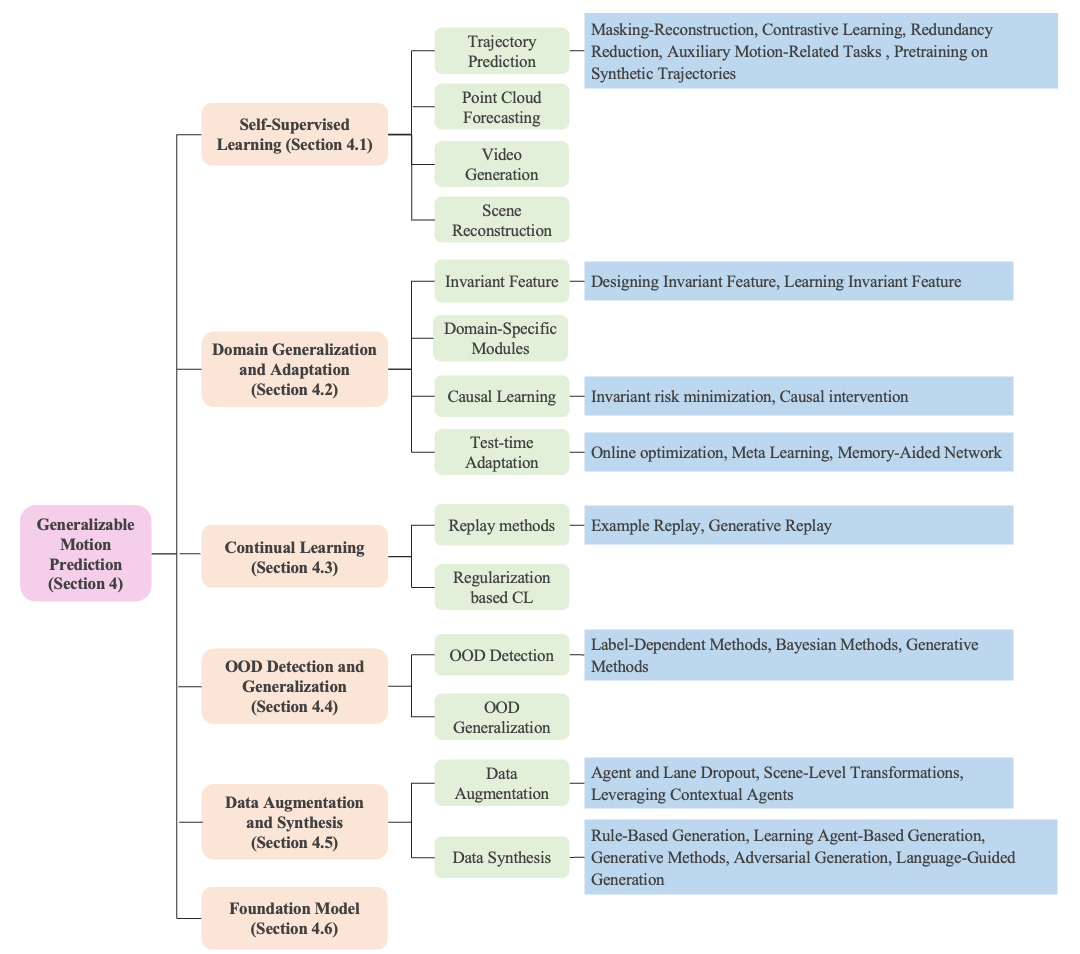
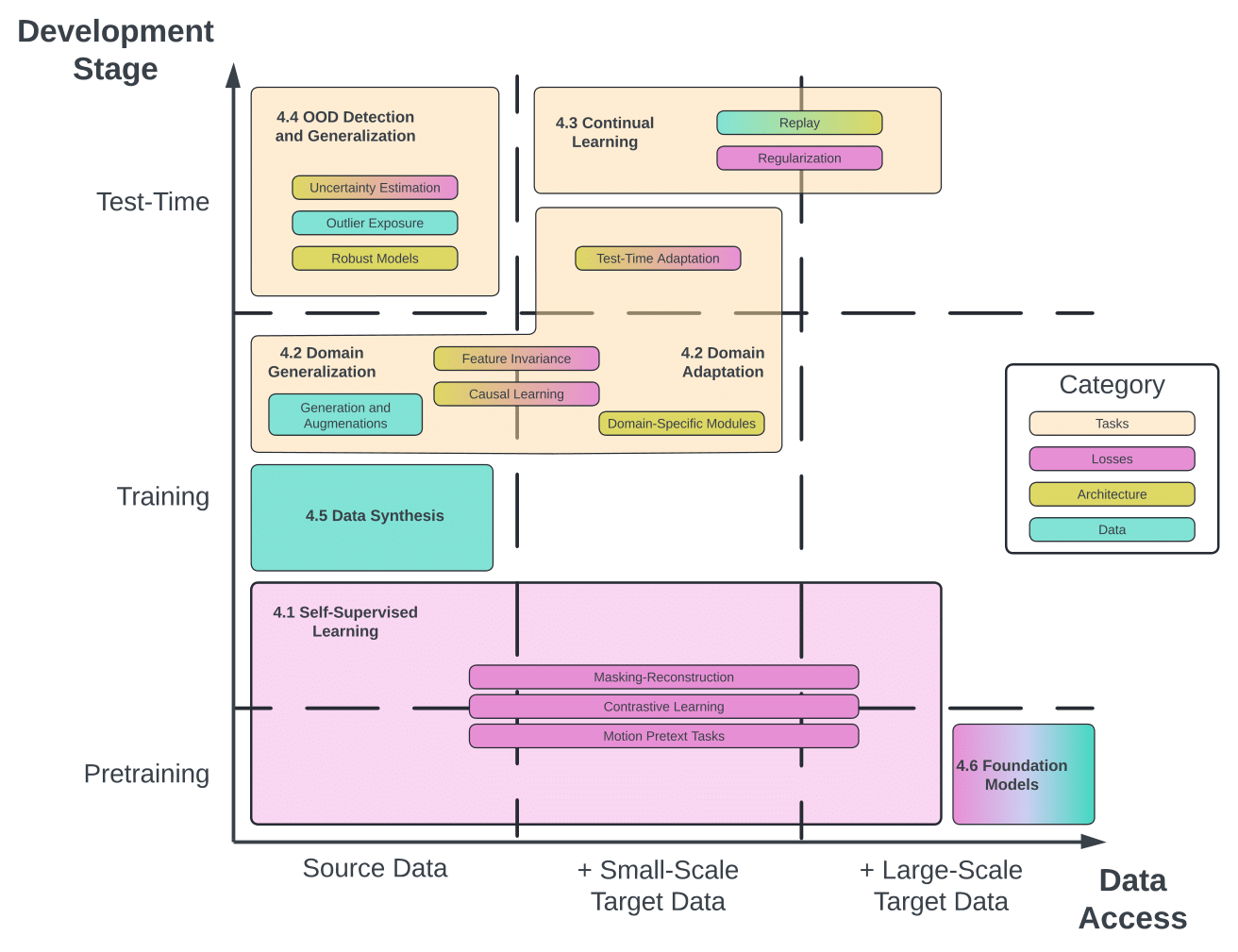
As motion prediction systems are deployed in increasingly diverse and unpredictable environments,
generalization becomes a central challenge—requiring models not only to perform well on known domains
but also to adapt, recover, or remain robust in the face of distributional shifts and open-world settings.
Several key themes that emerge from our paper persist and present opportunities for future research.
Data Scaling and Distribution Understanding: Despite the demonstrated success of
large-scale datasets in NLP and computer vision, the field of motion prediction remains largely in a small-data regime due to the
costly and labor-intensive process of collecting and annotating motion data. For instance, leading autonomous driving datasets
such as Argoverse, Argoverse 2, and the Waymo Open Motion Dataset (WOMD) contain only 320K, 250K, and 480K data sequences,
respectively—orders of magnitude smaller than datasets in NLP (e.g., GPT-3's 400B-token CommonCrawl) or vision (e.g., JFT's 303M images).
This scarcity of data constrains models’ ability to learn rich and transferable representations, ultimately limiting their robustness
and generalization.
Therefore, a critical priority is scaling up high-quality datasets, either by unifying
existing sources to overcome format and definition discrepancies, by developping efficient data collection pipelines, or by leveraging data synthesis methods.
Meanwhile, as datasets scale, simply adding more data is not sufficient. Understanding and quantifying the underlying data distribution becomes essential to ensure diversity,
avoid redundancy, and guide efficient data usage. Tools are required to characterize dataset coverage, diversity, and scenario
difficulty, moving beyond low-level statistics or handcrafted metrics. This understanding is crucial for nearly every aspect of
the generalization lifecycle, such as fair and informative cross-dataset benchmarking, designing efficient learning paradigms with balanced data coverage (e.g. dataset distillation,
active learning), evaluating the novelty of newly collected or synthetic data, and guiding the design of generalizable models themselves.
Revolutionize Modelling and Learning Strategies:
Motion prediction introduces unique structural and temporal challenges that set it apart from vision
and language tasks. Unlike static images or discrete text, motion data consists of continuous trajectories
shaped by physical laws, spatial constraints, and multi-agent interactions. Generalizable models in this domain
must therefore learn representations that generalize across diverse scene layouts, agent types, behavioral patterns,
and geographies—while respecting the causal and temporal dependencies inherent in real-world motion.
To this end, several key questions remain open. What inductive biases, tokenization strategies, or architectural modules
are best suited to represent agents, maps, and interactions effectively? Should representations be built on trajectory-level
abstractions or raw sensor streams like point clouds and videos—which bypass annotation and offer richer context, but
introduce high computational costs and struggle to capture discrete agent behaviors? More broadly, the optimal approach
for learning informative, transferable features across heterogeneous motion datasets remains unclear—highlighting the
need for further research into motion-specific pretraining objectives, scalable architectures, and adaptation strategies.
Ultimately, developing such models will require rethinking not only training but also deployment—encompassing how to fine-tune
models for specific downstream tasks, and how to ensure robust generalization under distribution shifts through
test-time OOD detection, generalization, and adaptation.
Establish Standardized Benchmarks and Unified Evaluation:
Although recent works have explored generalizable motion prediction through diverse perspectives—ranging from self-supervised learning and
domain adaptation to continual learning, OOD detection, and foundation models—the field remains in its early stages. While progress has been made,
many methods are still exploratory and fragmented, hindered by the lack of standardized evaluation protocols. In particular, the absence of
widely accepted cross-dataset benchmarks contributes to this fragmentation: each paper often adopts its own customized setting—e.g., specific
data scales, shift types, or evaluation metrics—making it difficult to fairly compare methods, assess their generality, or track progress across
the field.
Future efforts should focus on establishing unified and realistic evaluation protocols that span multiple tasks,
data regimes, and evaluation metrics. In contrast to classification, where OOD can be defined by unseen labels, benchmarking in regression tasks
like motion prediction requires more nuanced definitions, moving beyond coarse-grained approaches that treat entire different datasets as OOD. Evaluations
should also go beyond accuracy to include uncertainty estimation, which is essential for safety-critical downstream applications. Moreover,
fair comparisons under equal compute budgets are necessary to ensure meaningful assessment of progress.
Unleash the Power of Foundation Models: As data understanding, generalization methods,
and benchmarking continue to mature, foundation models are emerging to unify and extend these capabilities—offering a path toward robust
generalization in the open world. This paradigm builds on transformative advances in computer vision and natural language processing, where a large-parameter model trained with
a large amount of data shows strong zero-shot and few-shot generalization across diverse tasks and modalities.
This emerging trend includes two complementary directions:
1) Developing Motion-Specific Foundation Models: There is a growing need to
design large models tailored for the structured and dynamic nature of motion data. This involves unifying diverse datasets,
rethinking tokenization and architectural priors, and developing adaptation strategies across agents, geographies, and scenarios.
2) Adapting Existing Foundation Models: Given the relatively limited motion
data, adapting general-purpose foundation models (e.g., LLMs, video generation models) trained on internet-scale corpora is
a promising but nascent direction. These models offer emergent reasoning and common-sense capabilities that could benefit
motion tasks, but challenges remain in bridging modality gaps, aligning spatial-temporal reasoning with physical constraints,
and ensuring safe integration into real-world systems. Exploring their potential for zero- and few-shot generalization in
motion prediction is a key research opportunity.
In essence: the unique robustness to open world distribution shifts that is natural for humans may be an emergent property of
large scale models, and the path to achieving human-like performance in prediction systems may be a matter of further scaling
up large foundation models. This aligns with "Bitter Lesson", which emphasizes the simple
importance of scaling up resources over custom-tailored algorithms and architectures.